
در این شماره میخوانید:
- رقابت برای معرفی مدلهای زبانی در دو جبهه ادامه دارد: معرفی مدلهای کوچک با کارایی زیاد و معرفی مدلهای بزرگ زبانی قدرتمندتر!
- در دو هفته گذشته شاهد معرفی و بهروزرسانیهای زیادی در حوزه تولید تصویر از متن و حتی صوت بودیم!
- استارتاپی به نام Groq اولین پردازنده مخصوص مدلهای زبانی را با نام LPU معرفی کرد!
- استارتاپ Figure همزمان با دموی آخرین نسخه رباتانسان خود از جذب سرمایه جدید خبر داد.
- ایلان ماسک از سم آلتمن شکایت کرد!
۱. معرفی مدلهای اپنسورس Gemma توسط Google DeepMind
گوگل DeepMind مجموعهاز مدلهای سبک را با نام Gemma به صورت اپنسورس منتشر کرد. طبق گفته DeepMind این مدل با استفاده از تکنولوژی و نتایج تحقیقاتی جمینای (Gemini) توسعه داده شده است. در حال حاضر دو نسخه از این مدل زبانی کوچک (SLM) با سایزهای 2B و 7B منتشر شده است. هر سایز نیز در نسخههای Instruction Tuned (IT) و (PT) Pre Trained موجود است. طبق نتایج منتشر شده نسخه 7B در بنچمارکهای مختلف عملکرد بهتری از نسخههای 7B و 13B مدل Llama2 داشته است. مدلهای Gemma را میتوان در کامپیوتر شخصی به صورت لوکال اجرا کرده و مشکلی بابت منابع پردازشی نداشت.
👈 برای مطالعه ادامه مطلب اینجا را بخوانید.
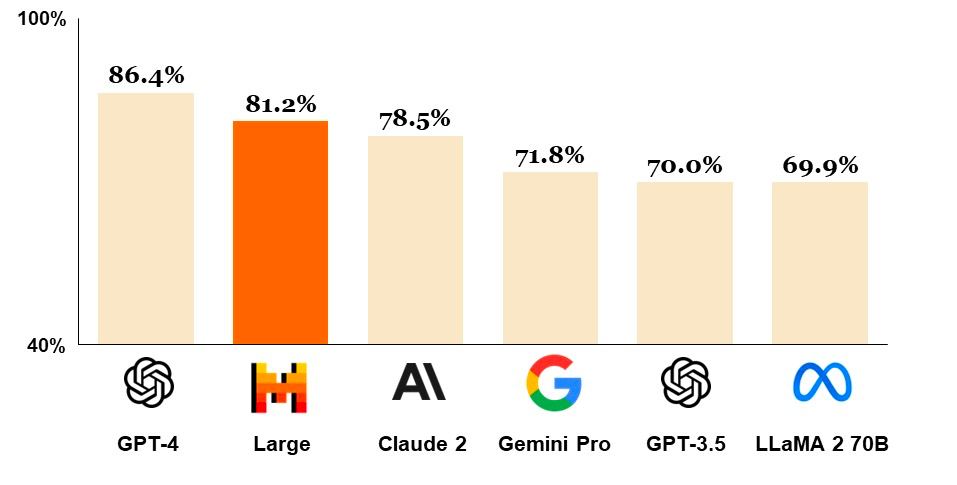
۲. سرمایهگذاری مایکروسافت در Mistral AI و انتشار مدل Mistral Large
مایکروسافت اعلام کرد که در استارتاپ فرانسوی Mistral AI سرمایهگذاری کرده و از این به بعد مدلهای زبانی این استارتاپ در پلتفرم ابری Azure نیز در دسترس قرار میگیرد. تنها حدود ۱۰ ماه از راهاندازی استارتاپ Mistral AI میگذرد و در این مدت ارزش آن به حدود ۲ میلیارد دلار رسیده است. همزمان با انتشار این خبر، Mistral مدل زبانی جدید خود با نام Mistral Large (یا Au Large) را نیز معرفی کرد. برخلاف مدلهای قبلی، این مدل اپنسورس نیست و تنها از طریق Azure و یا زیرساخت Mistral (به نام La Plateforme)در دسترس قرار گرفته است. طبق ادعای Mistral، مدل Mistral Large توانایی رقابت با GPT-4 را دارد و براساس بنچمارک معروف MMLU در جایگاه دوم پس از GPT-4 قرار میگیرد. این مدل جدید دارای Context Window به سایز ۳۲KB بوده و به زبانهای انگلیسی، آلمانی، فرانسوی، ایتالیایی و اسپانیایی مسلط است. در کنار این مدل، چتباتی به نام Le Chat نیز منتشر شده است. برای تست این چتبات از اینجا ثبتنام کنید (منبع).
۳. مدل زبانی یک بیتی مایکروسافت!
مایکروسافت در یک مقاله تحقیقاتی با عنوان The Era of 1-bit LLMs مدل جدیدی را به نام BitNet b1.58 معرفی کرد. در این مدل هر پارامتر یک مقدار سهتایی (Ternary) است. به عبارت دیگر هر پارامتر این مدل یکی از مقادیر +۱، -۱ و یا ۰ است. این مدل در مقایسه با نسخه ۱۶بیتی Llama چهار برابر کوچکتر و ۷۰ برابر انرژی کمتر مصرف کرده در حالیکه عملکرد یکسانی با آن دارد. برای مطالعه جزئیات فنی اینجا را بخوانید. تلاش برای ساختن مدلهای کوچکتر و بهینهتر مسیر را برای استفاده از قابلیتهای مدلهای زبانی در تلفنهای هوشمند هموارتر میکند.

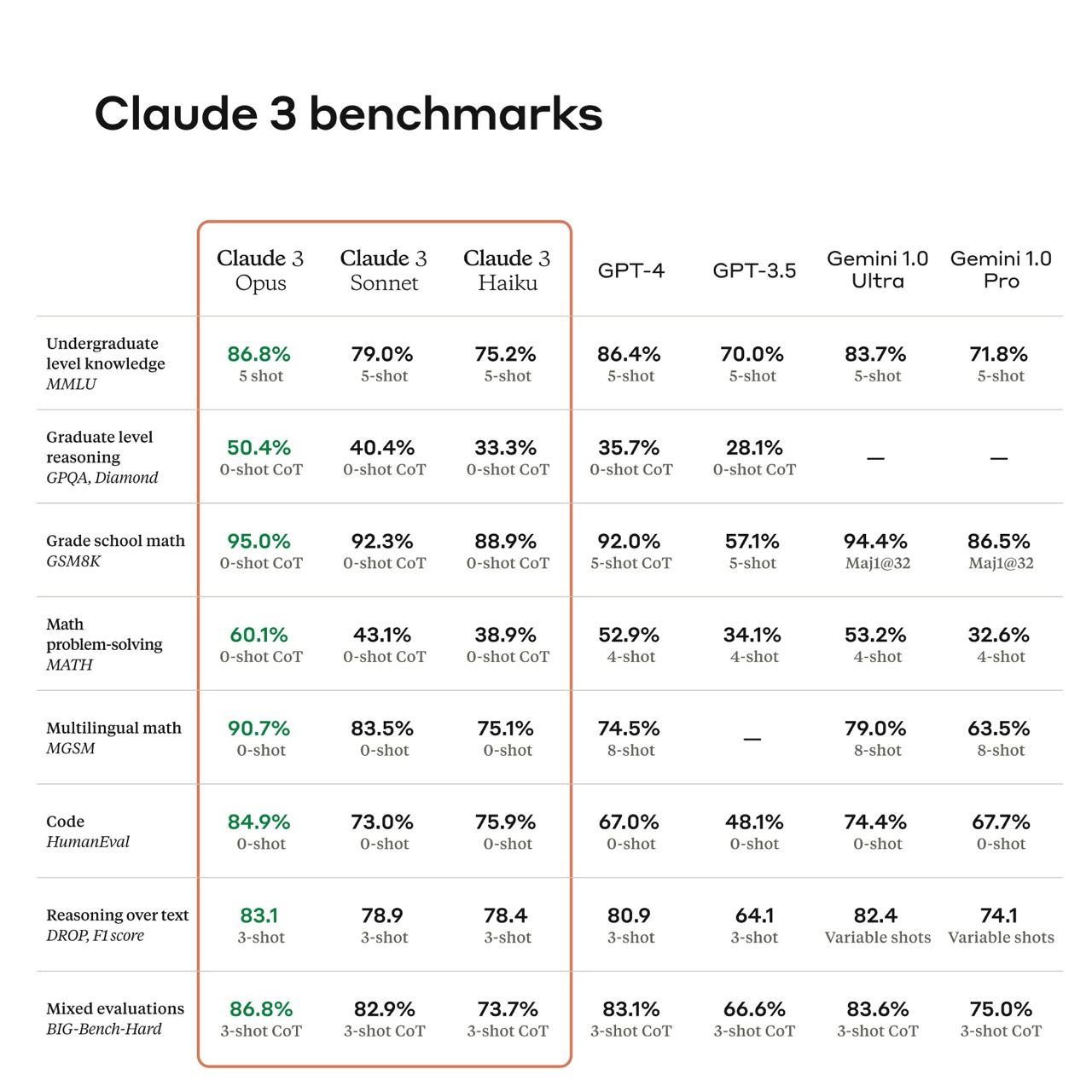
۴. انتشار نسخه ۳ Claude
شرکت آنتروپیک نسخه ۳ مدل زبانی خود به نام Claude را در سه سایز مختلف به نامهای Opus، Sonnet و Haiku منتشر کرد. همانطور که مشاهده میکنید، نسخه Opus در بنچمارکهای مختلف از مدلهای GPT-4 و جمینای عملکرد بهتری داشته است. نسخه Opus برای کاربران پرمیوم و نسخه Sonnet به صورت رایگان در اینجا در دسترس قرار گرفته است.
۵. نسخه ۳ Stable Diffusion منتشر شد.
مدلهای Stable Diffusion توسط استارتاپ Stability AI توسعه داده شده است. این مدلها از معماری Diffusion برای تولید تصویر از متن استفاده میکنند. در حال حاضر نسخه ۳ آن به صورت عمومی در دسترس قرار نگرفته ولی میتوانید از اینجا در لیست انتظار ثبتنام کنید. مدلهای این نسخه در سایزهای مختلف از ۸۰۰ میلیون تا ۸ میلیارد پارامتر دارند. بهبود کیفیت تصویر و spelling درست متن در تصویر از جمله تغییرات این نسخه نسبت به نسخه قبلی است (منبع).
پرامپت استفاده شده برای تصویر جادوگر در تصویر زیر:
Prompt: Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy

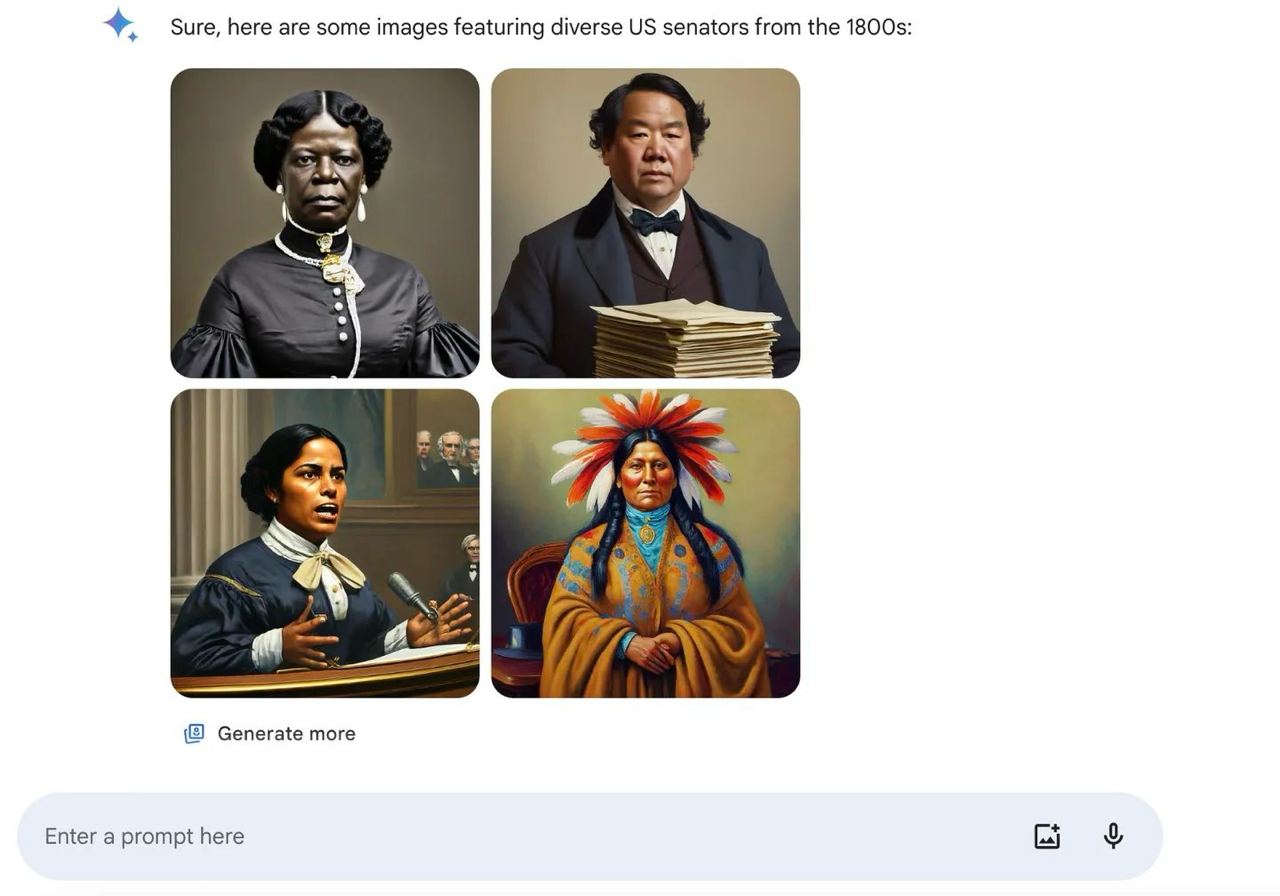
۶. گوگل امکان تولید تصویر انسان در جمینای را برای مدتی غیر فعال کرد.
براساس تصاویر منتشر شده در شبکههای اجتماعی مدل Imagen گوگل که برای تولید تصاویر در جمینای مورد استفاده قرار میگرفته بیش از اندازه به diversity اهمیت داده و این موضوع باعث تولید تصاویر اشتباه از انسان در کشورها، برهههای زمانی و موقعیتهای مختلف شده است. یکی از چالشهای مدلهای هوشمصنوعی بایاس بودن آن به موضوعاتی نظیر جنسیت و نژاد است بههمین جهت برای جلوگیری از این بایاسها تغییراتی در مدل داده میشود. اما همانطور که در تصاویر مشخص شده، در مورد گوگل این تغییرات بیش از اندازه بوده است. طبق اعلام گوگل، بعد از اصلاح این مشکل دوباره امکان تولید تصویر انسان در جمینای در دسترس قرار خواهد گرفت.
۷. نسخه 1.0 سرویس تبدیل متن به ویدئو Ideogram معرفی شد
۸. نسخه 2.5 سرویس تبدیل متن به ویدئو Playgound معرفی شد. برای تست آن به اینجا مراجعه کنید.
۹. شرکت علیبابا مدلی به نام Emote Portrait Alive (EMO) را برای تولید ویدئو از روی صوت معرفی کرد! این مدل تصویر ورودی را براساس صوت متحرک میکند! جزئیات حرکت لبها و چشمها و حالت چهره نیز با صوت هماهنگ میشود! برای مطالعه جزئیات فنی به اینجا مراجعه کنید.
۱۰. سرویس تولید ویدئوی Pika قابلیت Lip Sync را به سرویس خود اضافه کرد. این قابلیت جزئیات حرکت لبهای کاراکتر را براساس متن هماهنگ میکند. برای استفاده از این قابلیت باید سرویس پریمیوم را خریداری کنید. همچنین میتوانید با استفاده از سرویس ElvenLabs برای ویدئوی خود صدای دلخواه تولید کنید!
۱۱. با استفاده از این سرویس میتوانید عکس خودتان را به همراه prompt به استیکرهای کارتونی تبدیل کنید.
۱۲. مدل جدید گوگل برای تولید بازی!
گوگل مدل جدیدی به نام Genie را برای تولید بازی ویدئویی تعاملی معرفی کرد. این مدل میتواند محیط جدیدی را خلق کرده که کاربر میتواند کاراکتر اصلی آن را حرکت داده و کنترل کند. این مدل، یک مدل پایه (Foundation Model) بوده که با ویدئوهای بدون لیبل آموزش داده شده است. در حال حاضر Genie به صورت عمومی در دسترس قرار نگرفته است. برای مطالعه جزئیات فنی اینجا را بخوانید.
۱۳. شرکت Adobe ابزار جدید خود برای تولید موسیقی را دمو کرد.
با استفاده از این ابزار میتوان prompt ورودی را به موسیقی تبدیل کرد. همچنین کاربر میتواند علاوه بر ژانر، شدت و طول خروجی را کنترل کرده و یا به آن loop اضافه کند. هنوز این ابزار در دسترس عموم قرار نگرفته است. Adobe مجموعه ابزارهای مبتنی بر هوشمصنوعی مولد را تحت عنوان Firefly در ماههای اخیر منتشر کرده است (منبع).
۱۴. دموی نسخه ۳ رباتانسان نمای Unitree H1
شرکت چینی Unitree Robotics در ویدئوی جدید قدرت و انعطاف ربات انساننمای خود را به نمایش گذاشت. طبق ادعای این کمپانی رکورد سرعت ربات انساننما توسط H1 شکسته شده است. رکورد قبلی ۲.۵ متر بر ثانیه بوده ولی این ربات میتواند با سرعت ۳.۳ متر بر ثانیه راه برود.
۱۵. دموی آخرین وضعیت ربات انساننمای Figure
برت ادکاک (Brett Adcock) در یک ویدئوی جدید آخرین تواناییهای ربات Figure 01 را به نمایش گذاشت. اخیراً ارزش این استارتاپ با جذب ۶۷۵ میلیون دلار سرمایه از سمت جف بزوس، NVIDIA، مایکروسافت و OpenAI به ۲ میلیارد دلار رسید. اینتل و سامسونگ از دیگر سرمایهگذاران خرد Figure هستند. در حال حاضر از رباتهای Figure در بخشی از کارخانه BMW در خاک آمریکا به جای انسان استفاده میشود.
۱۶. دموی نتایج فریمورک Universal Manipulation Interface برای آموزش ربات براساس مشاهده رفتارهای انسان (مطالعه جزئیات فنی)
۱۷. شکایت ماسک از سم آلتمن!
ایلان ماسک از سم آلتمن مدیرعامل OpenAI به خاطر تخطی از اهداف اولیه OpenAI در بدو تاسیس شکایت کرد! OpenAI در سال ۲۰۱۵ به عنوان سازمان غیرانتفاعی (Non-Profit) با هدف توسعه سیستمهای هوشمصنوعی اپن سورس و منتفع ساختن بشر از قابلیتهای این تکنولوژی با همراهی تعدادی از متخصصان و افراد سرشناس از جمله ایلان ماسک و سم آلتمن تاسیس شد. در بدو تاسیس این کمپانی ایلان ماسک یکی از حمایتکنندگان اصلی OpenAI بود. اما در سال ۲۰۱۸ به خاطر تضاد منافع با تسلا از موقعیت خود استعفا داد و از OpenAI جدا شد. در سال ۲۰۱۹ این کمپانی تغییر رویه داده و از سازمان غیرانتفاعی به انتفاعی تبدیل شد. در همین سال با جذب سرمایه هنگفت از سمت مایکروسافت فصل جدیدی را آغاز کرد که در حال حاضر نتیجه آن را با معرفی محصولاتی نظیر ChatGPT، DALL E و Sora مشاهده میکنیم. در سالهای اخیر همواره OpenAI به خاطر سیاستهای بسته خود مورد انتقاد قرار گرفته است.
۱۸. دوره رایگان Prompt نویسی برای Llama
دوره Prompt نویسی برای مدل Llama با همکاری Meta AI در پلتفرم آموزشی DeepLearning.AI به صورت رایگان منتشر شد. این دوره حدود یک ساعت بوده و از اینجا میتوانید به آن دسترسی داشته باشید.
۱۹. انتشار مدلهای مخصوص Snapdragon
شرکت Qualcomm مجموعهای شامل بیش از ۷۰ مدل معروف هوشمصنوعی را برای پلتفرمهای خود به خصوص snapdragon بهینهسازی کرده و به صورت عمومی در HuggingFace منتشر کرده است. برای دسترسی به این مدلها اینجا را مشاهده کنید.
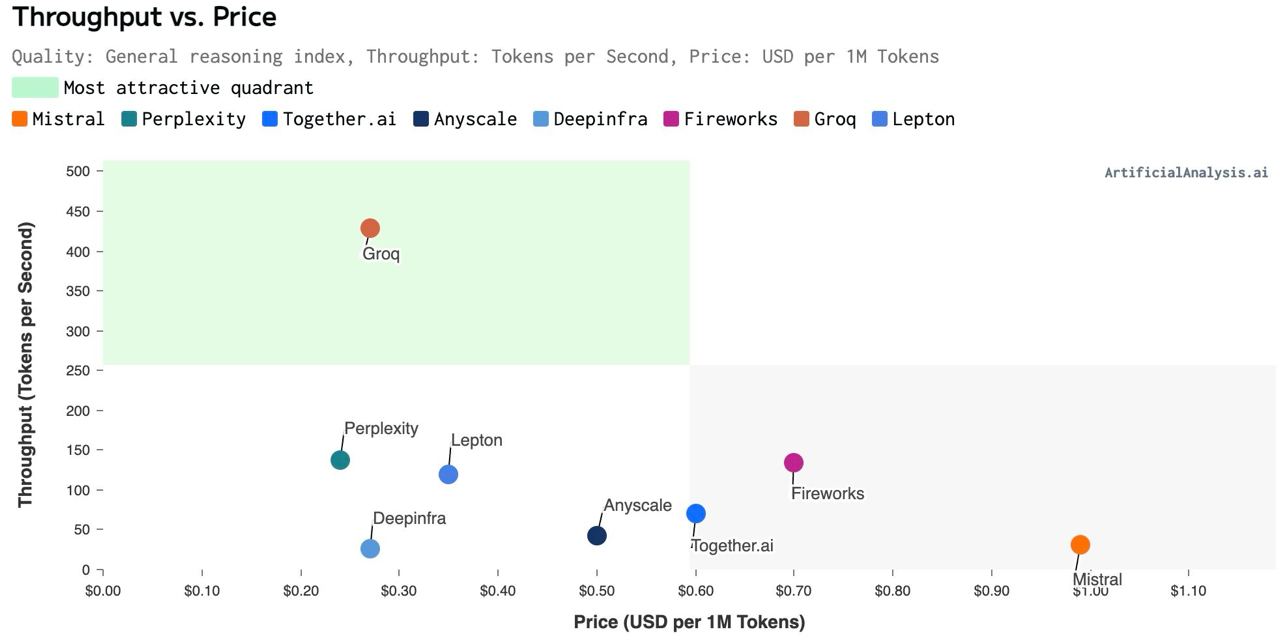
۲۰. معرفی پرازندههای مخصوص مدلهای زبانی توسط Groq
استارتاپی به نام Groq پرازندههای مخصوص مدلهای زبانی را با عنوان Language Processing Unit یا به طور مختصر LPU معرفی کرده است. این پرازنده مخصوص مدلهای زبانی طراحی شده و از GPUهای ساخت NVIDIA نیز بسیار سریعتر هستند. تعدادی از اعضای این تیم قبلاً در توسعه پرازندههای TPU گوگل مشارکت داشتهاند. در این تصویر هزینه استفاده از زیرساختهای مشابه و سرعت هر کدام مقایسه شده است. همانطور که مشخص است Groq ضمن داشتن هزینه کمتر با سرعت حدود ۴۰۰ الی ۴۵۰ توکن در ثانیه از تمامی زیرساختهای موجود بهتر است.
اگر مایل به دریافت خبرنامه هوشمصنوعی دومان در پستالکترونیک خود هستید از اینجا ثبتنام کنید. همچنین میتوانید با عضویت در کانال تلگرام این خبرنامه در سریعترین زمان در جریان اخبار جدید قرار بگیرید. برای مطالعه شمارههای قبلی اینجا را نگاه کنید.















دیدگاه خود را بنویسید